The Programming AI Hype vs. Reality: What New Research Actually Shows
• 5 min readLarge Language Models (LLMs) have recently improved thanks to new techniques like "thinking mode", introduced by the company DeepSeek. We hear of claims that LLMs outperform humans in programming. Programming might be entirely replaced by LLMs soon.
Is that real?
First of all, who claims that? Actually, people who claim that are often founders of AI companies, and their suite of AI influencers. The latter benefit directly from such claims, while the former benefit from exaggerating and get more clicks for their posts. We might challenge this fact.
Actually, when programming myself, I realize how much more productive LLMs makes me. But I also clearly see the current limits of LLMs in programming. Neutral AI influencers see it as well. Check Simon Willison’s [blog](https://simonwillison.net/2025/Mar/11/using-llms-for-code/), who mentions that he uses LLMs for programming but avoids the hype around it. What he experiences is by far not what he reads on X.
Where do these claims come from? Are these claims real? Let's check the recent research on this topic.
To assess the performance of an LLM, researchers come up with benchmarks. There are a series of tests that LLMs go through, and they typically measure the success rates. For programming, the benchmark [LiveCodeBench](https://livecodebench.github.io/) is used. They collect problems from periodic contests. If an LLM performs well at this benchmark, it is considered good at programming.
But the problem is that the tests used for these benchmarks become public (somehow). By being public, they land in the training data of LLMs, which means LLMs are trained on these exact same problems they are evaluated on - which obviously they can solve easily!
Recently, researchers have come up with a new benchmark, [LiveCodeBench Pro](https://livecodebenchpro.com/). This benchmark is continuously updated and only the most recent problems are included. Those that are not yet public, and hence problems that are not used by LLMs for their training. In other words, the benchmarks are not contaminated. How do LLMs perform on these benchmarks?
## Low performance on hard problems
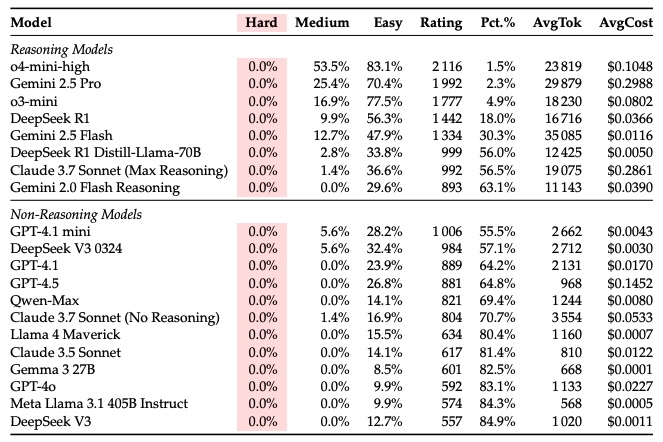
You read it right: All LLMs solve... 0% of hard programming problems!
How do they fail? The researchers have classified the problems and looked deeper into them. They classify them into:
- **Knowledge-heavy:** Problems that require specific algorithms, formulas, or code patterns that you either know beforehand or you don't.
- **Logic-heavy:** Problems that require careful step-by-step reasoning and mathematical thinking.
- **Observation-heavy:** Problems that require spotting a key insight or "aha" moment from the problem description.
Looking at more granular results, below you can see the performance of LLMs compared to human level.
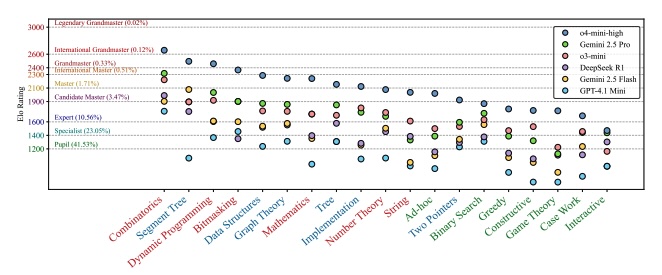
LLMs have different success rates depending on the type of problems. Especially, they do not outperform humans in the way people claim they do.
Comparing LLMs with humans below again, where it is shown at what LLMs/humans fail. The ratio X:Y shows the number of errors for LLMs (X) vs. Humans (Y).

## Reasoning does not always help
The researchers have also compared results with and without "thinking mode", which is the breakthrough that was introduced by the company DeepSeek, which was able to train an LLM at a fraction of the costs of traditional LLMs, thanks to this new approach.
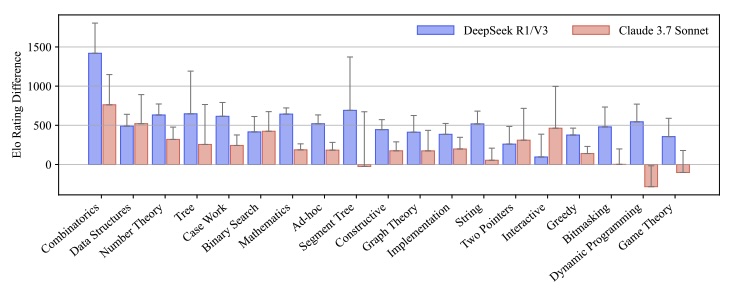
The chart above shows the performance gain of using the thinking mode versus not using it, for two frontier models (DeepSeek and Claude). As can be seen on this chart, the thinking mode helps in some cases (like in combinatorics problems) but does not help everywhere.
## Analysis of failures
The researchers found the following results (quoted from the article):
- LLMs perform better on knowledge-heavy and logic-heavy problems, and worse on observation-heavy problems or case work.
- o3-mini makes significantly more algorithm logic errors and wrong observations, and many fewer implementation logic errors than humans.
- Increasing the number of attempts significantly improves the performance of the models while still failing in the hard tier.
- Reasoning brings about the largest improvement in combinatorics, a large improvement in knowledge-heavy categories, and relatively low improvement in observation-heavy ones.
## Conclusion
In summary, the hype around LLMs completely outperforming humans in programming is significantly overstated. The LLMs seem to perform where patterns can be applied, while they fail where innovative solutions are required to solve a problem. This confirms the assumption that LLMs do not "think". Rather, they apply patterns that they have observed during their training. This is not enough to replace humans completely. Much more likely, we will observe a productivity increase through the use of AI assistants, but not a full replacement of human developers.
This observation likely holds for other domains. Programming is a domain that is at the forefront of Generative AI. Reasons are multiple. First of all, people programming the models are the same as those programming. The "programming" use case is therefore the perfect match because the developers know what problems they face daily, and try to solve them. Second, programming returns a wrong or a correct answer. It can be easily assessed. And improved via a "reward function". This is far less obvious for use cases like writing an investment report, which has no right or wrong output.
Based on these observations of clear limitations of LLMs, we believe that the future will not consist of LLMs solving problems, disconnected from humans. We believe that LLMs will be integrated into workflows managed by humans—LLMs are just a new tool to increase our productivity.
## References
1. ["LiveCodeBench Pro: How Do Olympiad Medalists Judge LLMs in Competitive Programming?"](https://arxiv.org/pdf/2506.11928), Z. Zheng et al., 13th June 2025.

